
ChatGLM-6B模型部署
ChatGLM-6B模型部署
戈亓随着Chatgpt爆火以来,国内外各大互联网厂商纷纷开始相关的产业布局,纷纷推出自家的大模型,并规划将自己的大模型要接入自家的产品,于是乎我诞生了一个想法:我们实验室什么时候可以有自己的大模型可以接入实验室的项目,这样科技含量(含金量)岂不是可以大大增加。从头打造一个大模型无论是技术还是人力物力来说都不现实,但是最近一个多月来开源的文本大模型出现了很多,如果能将开源大模型作为预训练模型,能降低很多成本,于是乎我选择了清华大学开源的ChatGLM-6B模型,尝试部署和进行一些简单的训练。
ChatGLM-6B 是什么?
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
ChatGLM-6B 部署
下载源码
1 | git clone https://github.com/THUDM/ChatGLM-6B |
安装依赖
1 | 进入项目根目录 |
下载模型文件
1 | git clone https://huggingface.co/THUDM/chatglm-6b |
量化后的模型文件下载地址如下:
项目启动
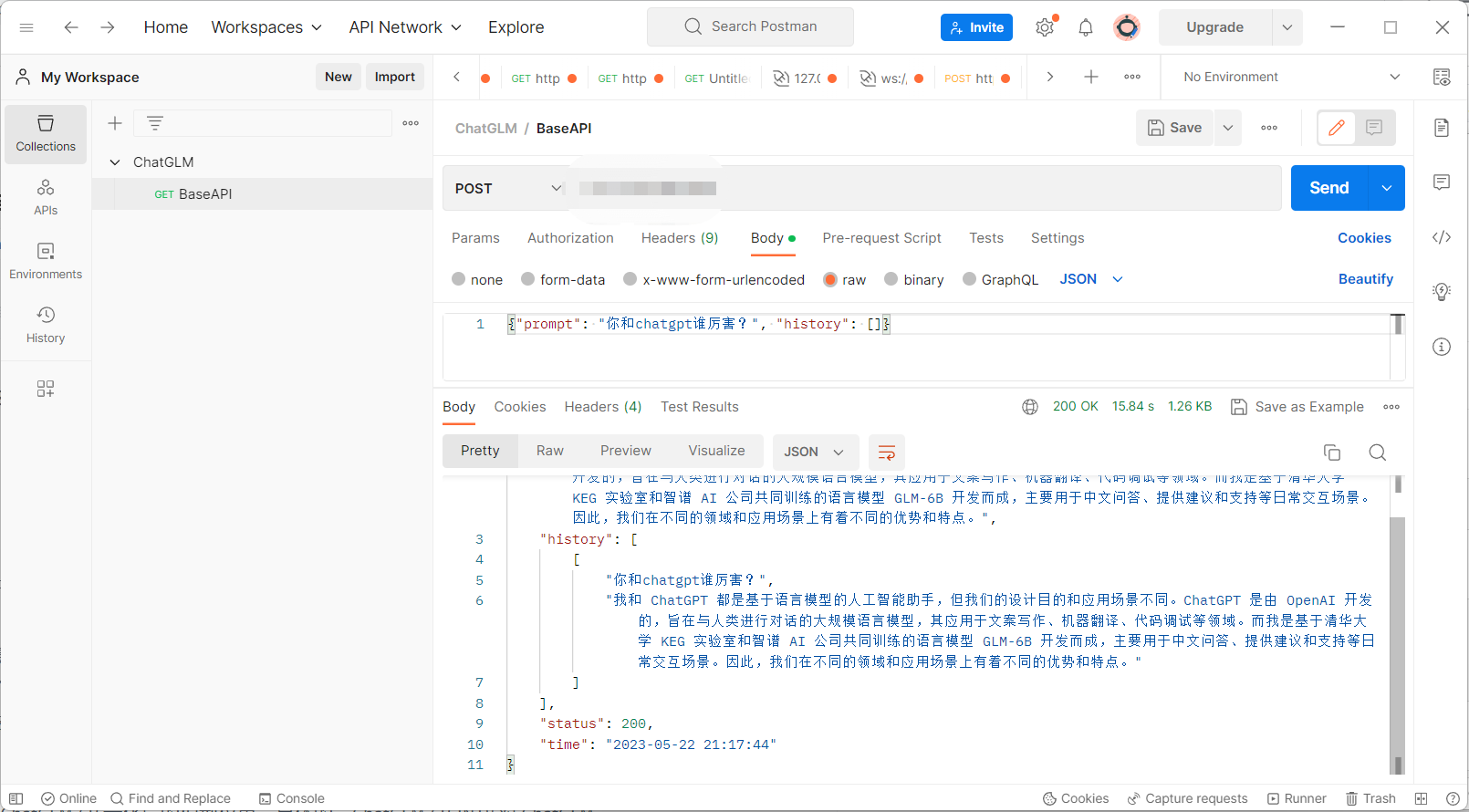
API模式
1 | pip install fastapi uvicorn |
postman测试端口
命令行模式
1 | python cli_demo.py |

网页模式
1 | pip install gradio |
后续会在复习之余尝试进行模型微调和NLP的学习。






